Appearance

大模型评测 ModelS_Eval平台
项目介绍
ModelS-Eval 多模型智能评测平台 是一款具备跨厂商、跨平台兼容性的综合性评测系统.该平台支持对私有化部署模型进行并行对比评估,用户仅需提交单份测试数据集(含多轮对话样本),即可实现多模型响应质量的同步自动化评测.其核心优势包括:
- 多模态支持能力:兼容文本、图像、视频等多种数据类型的输入评测
- 全场景覆盖:适配国内外主流公有云服务、私有云环境、本地化部署的大语言模型及智能体平台
- 统一评测框架:提供标准化的评估体系,实现异构模型间的性能横向对比
- 安全可控的私有化部署:支持本地化部署,代码开源且未加密,客户可在私有网络环境中独立运行,确保数据与模型评测过程的安全性和隐私性,避免敏感信息外泄
- 灵活可扩展:基于开源架构,用户可根据业务需求进行二次开发,定制专属评测流程
项目背景
当前,企业在评估大语言模型(LLM)时面临以下核心挑战:
跨平台评测能力缺失
- 现有评测工具通常仅支持单一厂商或平台,无法在同一环境下对比不同厂商(如 OpenAI、Claude、本地部署模型等)的性能表现,导致选型决策缺乏客观依据.
业务数据安全与部署限制
- 敏感业务数据因合规要求无法上传至公有云平台,而本地部署的模型又缺乏标准化评测工具,形成“数据不上云则无法评测,上云则存在泄露风险”的矛盾.
评测结果与实际体验脱节
- 部分平台在封闭测试环境中表现优异,但实际业务场景中响应速度慢、回答质量不稳定,现有工具无法模拟真实客户端请求进行端到端验证.
智能体平台兼容性不足
- 企业需同时评估多个智能体平台(如 Coze、Dify 等)的回复准确性,但缺乏统一平台支持多智能体的并行测试与结果对比.
决策支持需求明确
- 需生成结构化评测报告,直观展示各模型在响应速度、回答质量、稳定性等维度的量化对比,供管理层决策参考.
ModelS-Eval 的解决方案
针对上述痛点,ModelS-Eval 多模型智能评测平台 提供以下能力:
全场景跨平台评测
- 支持同时接入公有云 API、私有化部署模型及智能体平台,在统一环境中发起对比测试,消除数据孤岛.
安全优先的私有化部署
- 提供开源、未加密的本地部署方案,确保敏感数据全程不出私网.
真实业务场景模拟
- 支持从企业客户端直接发起测试请求,捕获真实网络环境下的模型表现(如延迟、错误率),避免“实验室数据失真”.
多智能体并行评测 (未实现)
- 可配置多个智能体平台(如 Coze、Dify)的测试流程,自动校验回复是否符合预期逻辑.
自动化报告生成 (未实现)
- 输出多维度对比报告(含响应时延、准确率、成本分析等),支持自定义评分权重,辅助技术选型与采购决策.
痛点分析
1. 单平台无法测试多厂商大模型
痛点:现有评测工具通常仅支持单一厂商或平台(如仅测试 OpenAI 或仅测试本地模型),无法在同一环境下对比不同厂商(如 GPT-4、Claude、Gemini 等)的性能差异,导致选型决策缺乏客观依据.
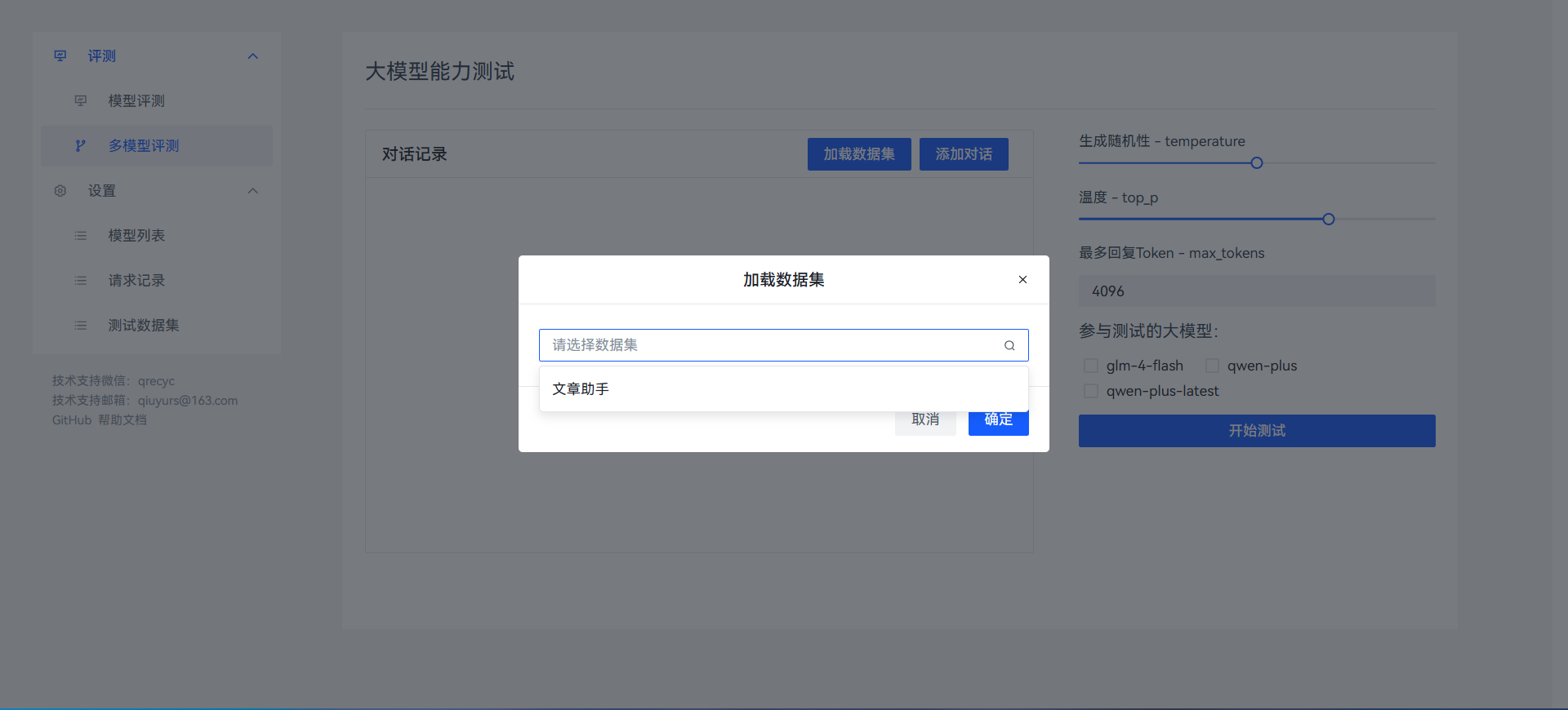
解决方案:ModelS-Eval 支持跨厂商、跨平台模型统一接入,用户可提交同一份测试数据,并行对比多个大模型的响应速度、回答质量及稳定性.
2. 无法测试私有化部署或微调后的模型
痛点:企业私有化部署或行业微调的大模型(如金融、医疗领域专属模型)无法在公有云评测平台上测试,导致优化效果难以量化评估.
解决方案:支持本地化部署的模型接入,兼容 Hugging Face、vLLM 等开源框架,确保私有模型与公开大模型在同一标准下对比评测.
3. 无法对比微调模型与公开大模型的差异
痛点:企业微调后的模型优化效果缺乏量化对比,难以判断微调是否真正提升业务场景表现.
解决方案:提供 A/B 测试能力,支持微调模型与原始基座模型的同数据对比,输出准确率、流畅度、合规性等维度差异报告.
4. 无法模拟真实客户端场景,测试网络波动等影响
痛点:实验室环境测试结果与实际业务表现脱节,无法模拟客户端网络延迟、高并发请求等真实场景问题.
解决方案:支持从企业内网直接发起端到端请求测试,记录真实响应时间、错误率及网络抖动影响,避免“评测数据良好,实际体验糟糕”的情况.
5. 测试平台无法私有化部署,业务数据需上云
痛点:敏感数据(如金融交易记录、医疗问诊数据)因合规要求无法上传至第三方平台,导致无法评测.
解决方案:提供完全私有化部署方案,代码开源、未加密,客户可在隔离环境中运行,确保数据不出私网,满足 GDPR、等保等合规要求.
6. 测试平台不透明,数据安全无法保障
痛点:部分评测平台闭源运行,数据处理逻辑不透明,存在敏感信息泄露风险.
解决方案:采用白盒化架构,所有评测逻辑、数据处理流程可审计,支持客户自定义数据脱敏规则,确保评测过程安全可控.
主要功能
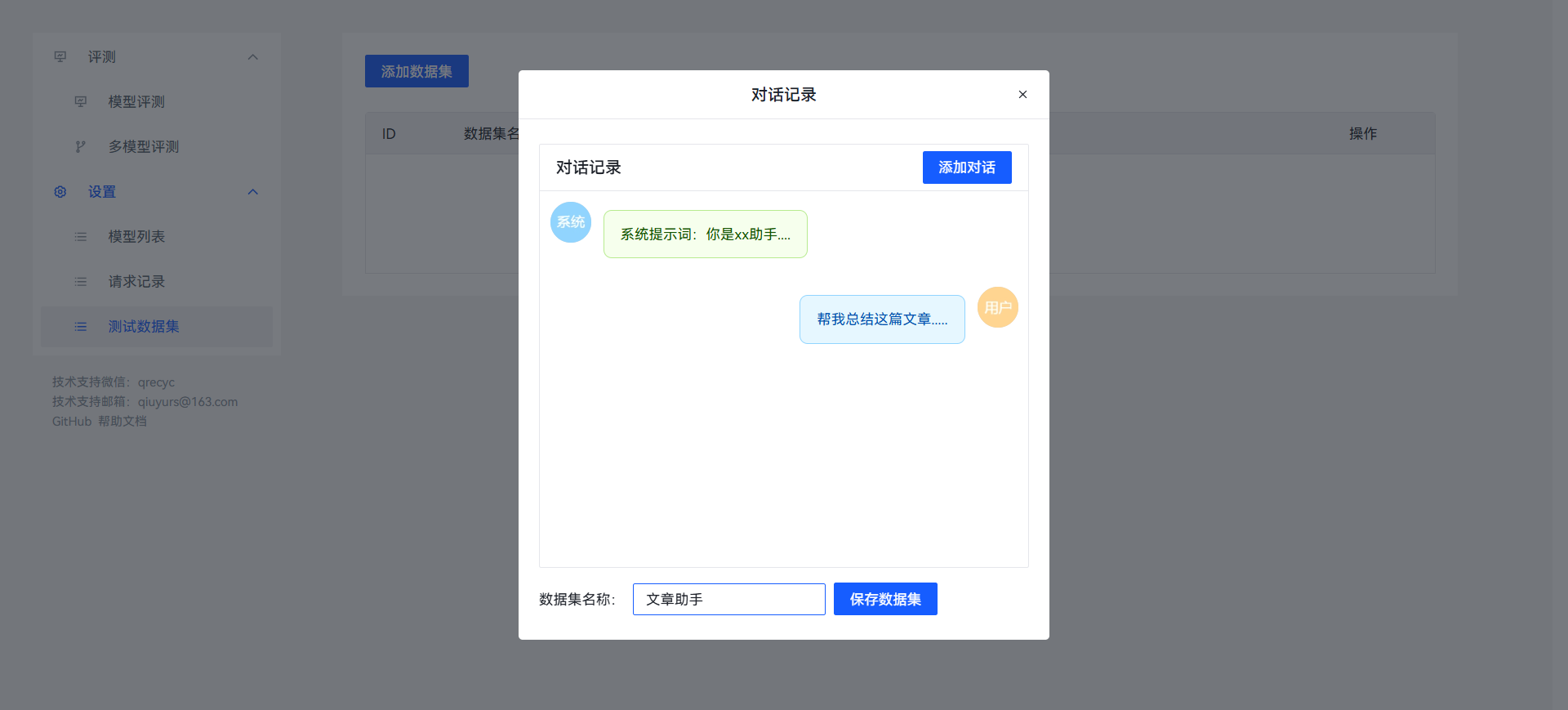
添加对话记录
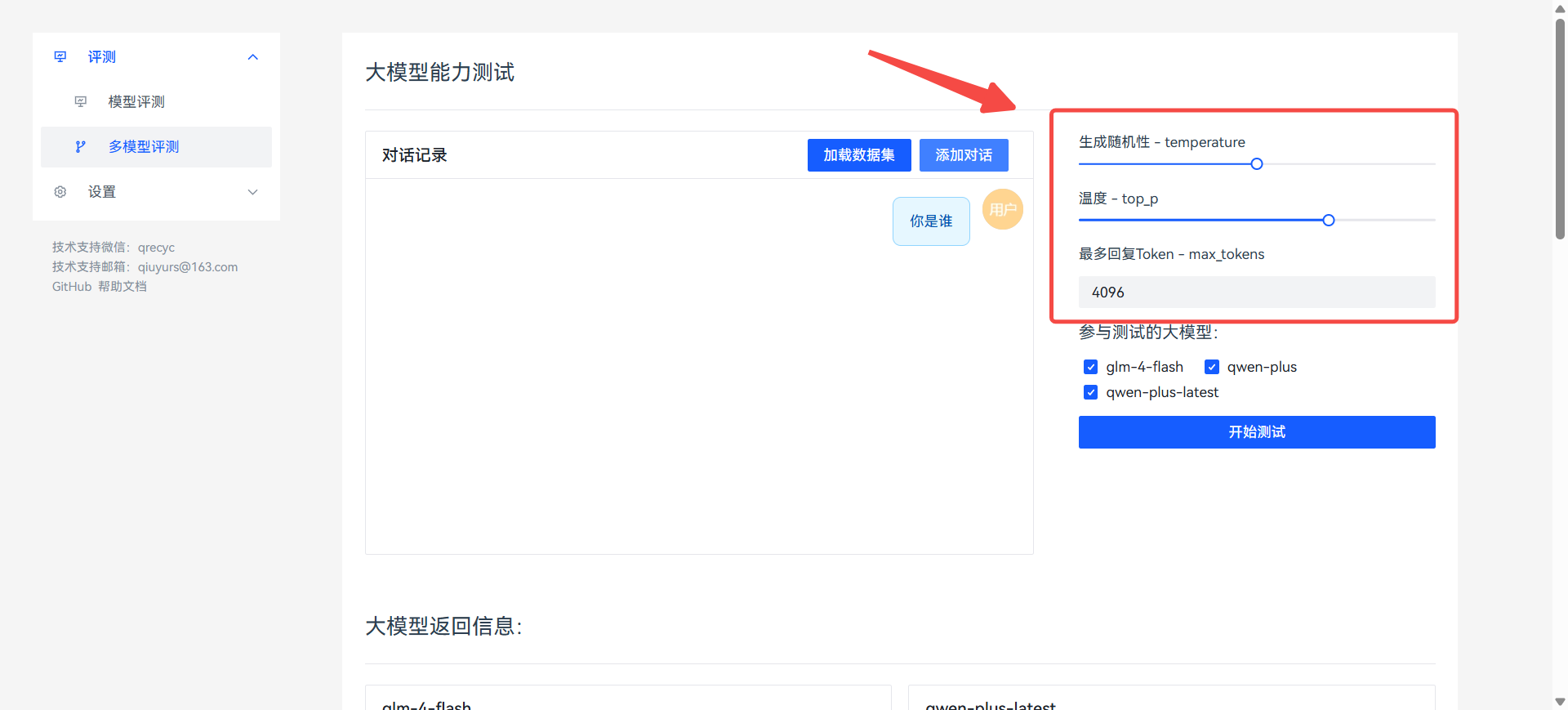
调整请求参数
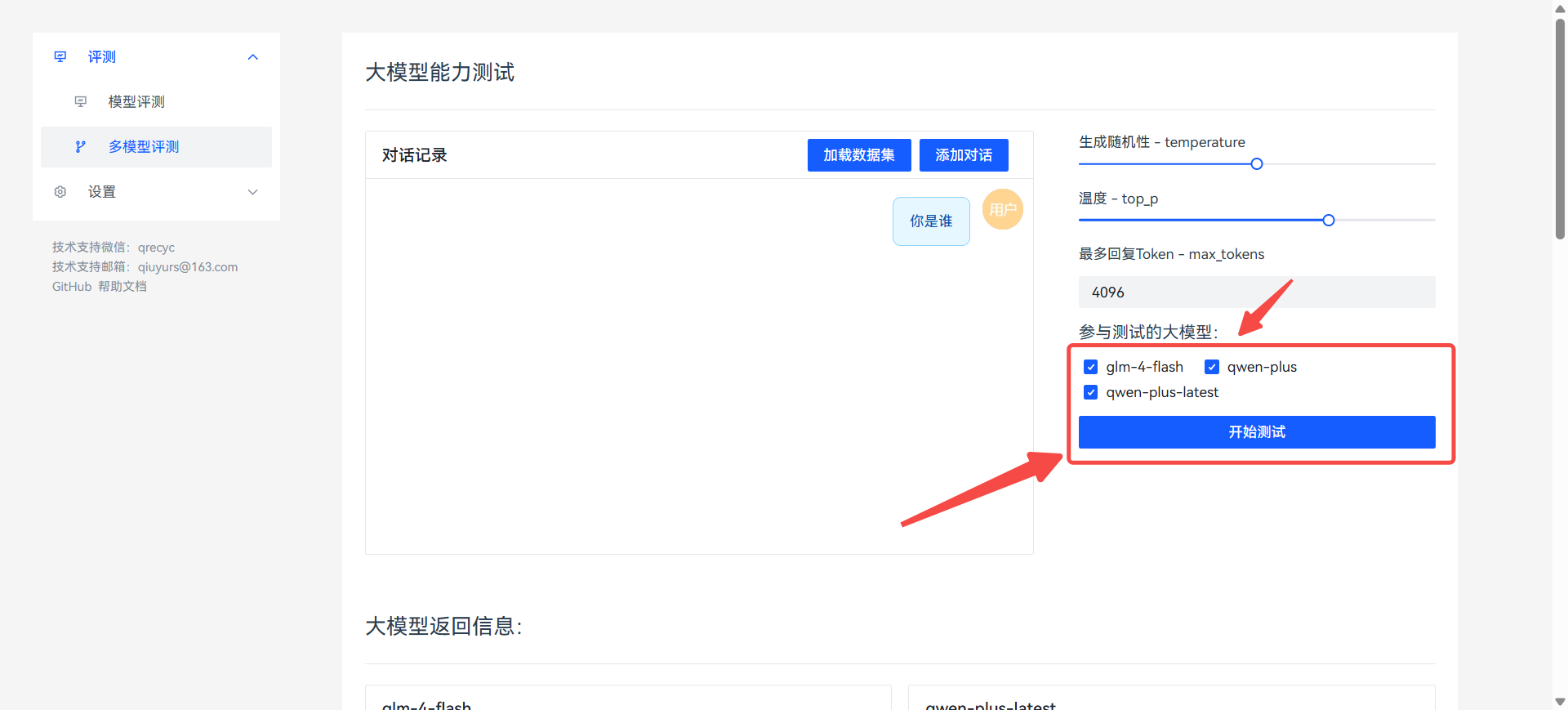
开始测试
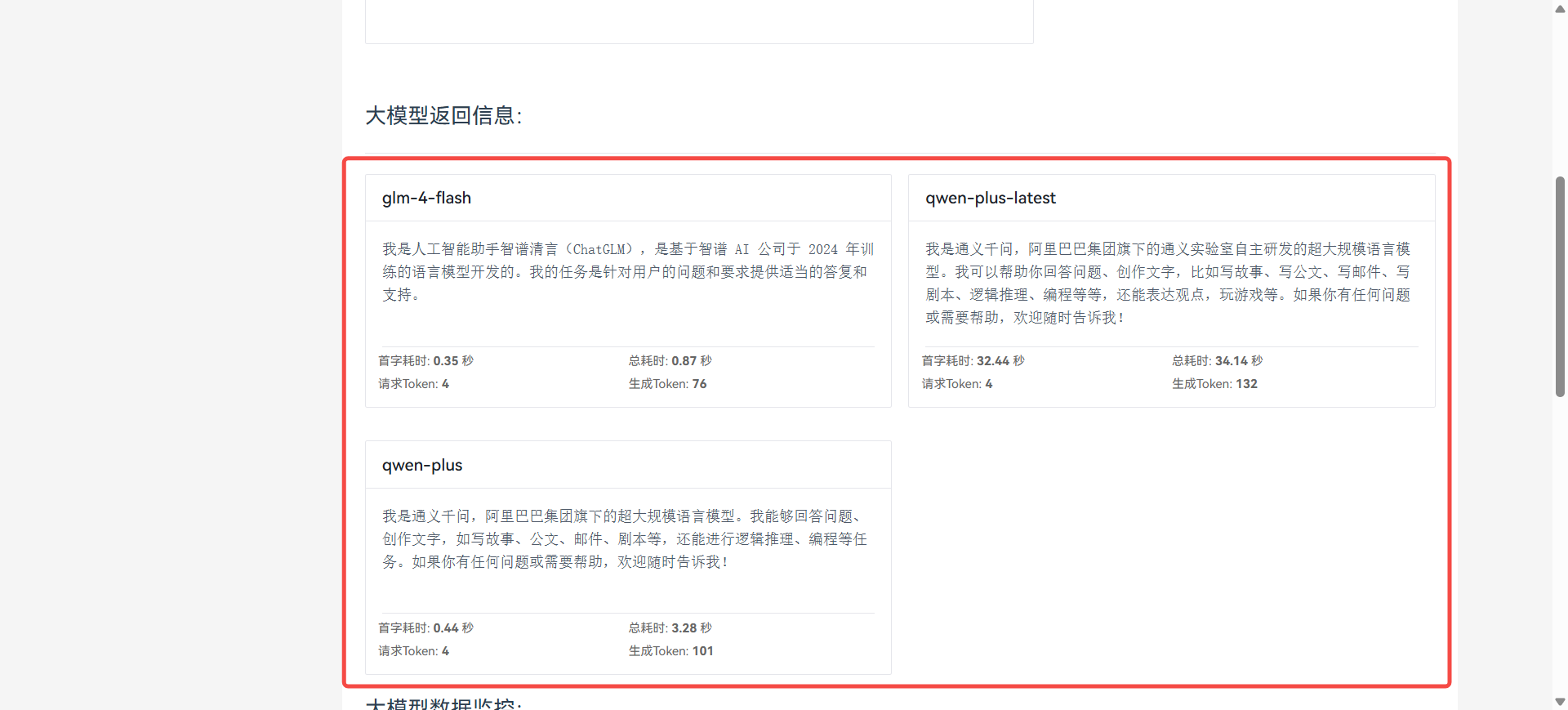
对比返回信息
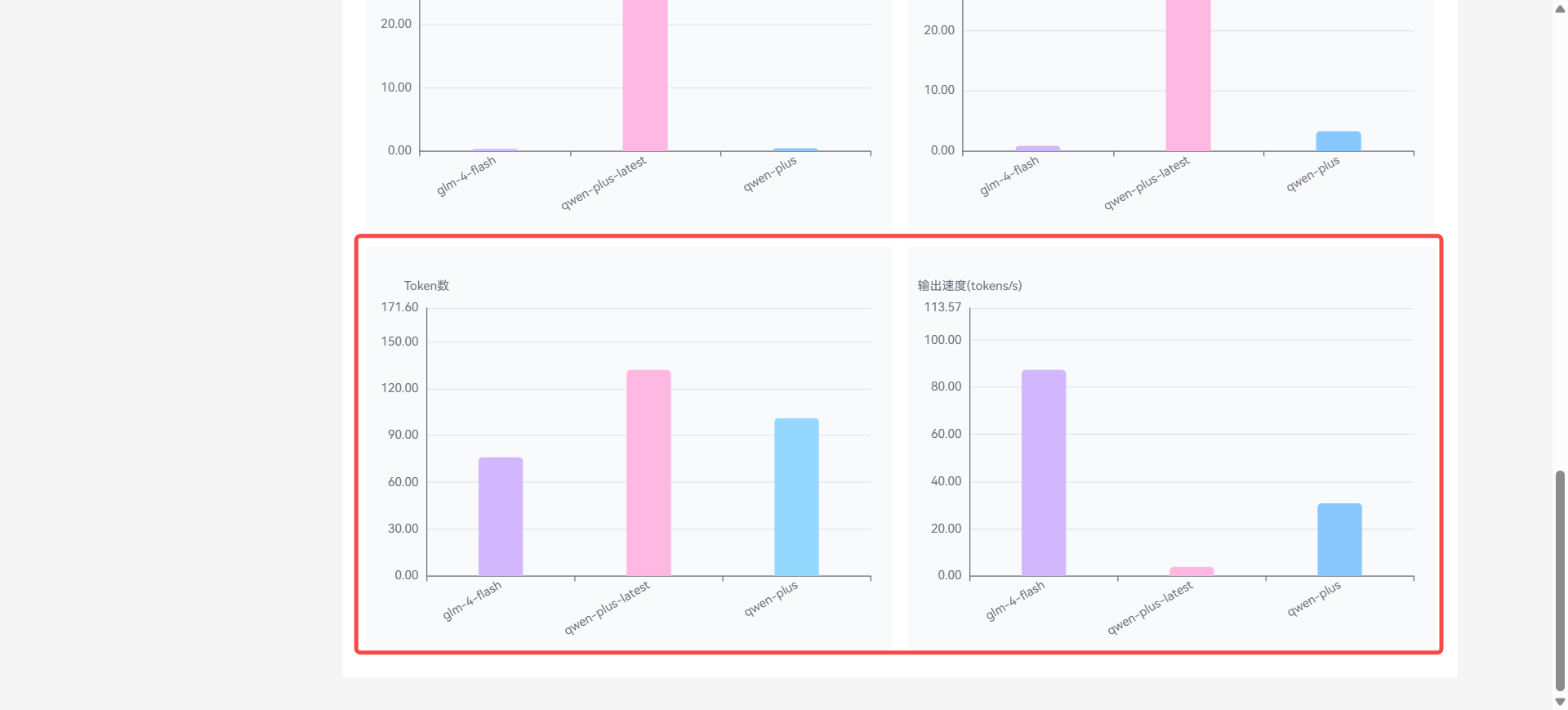
数据监控
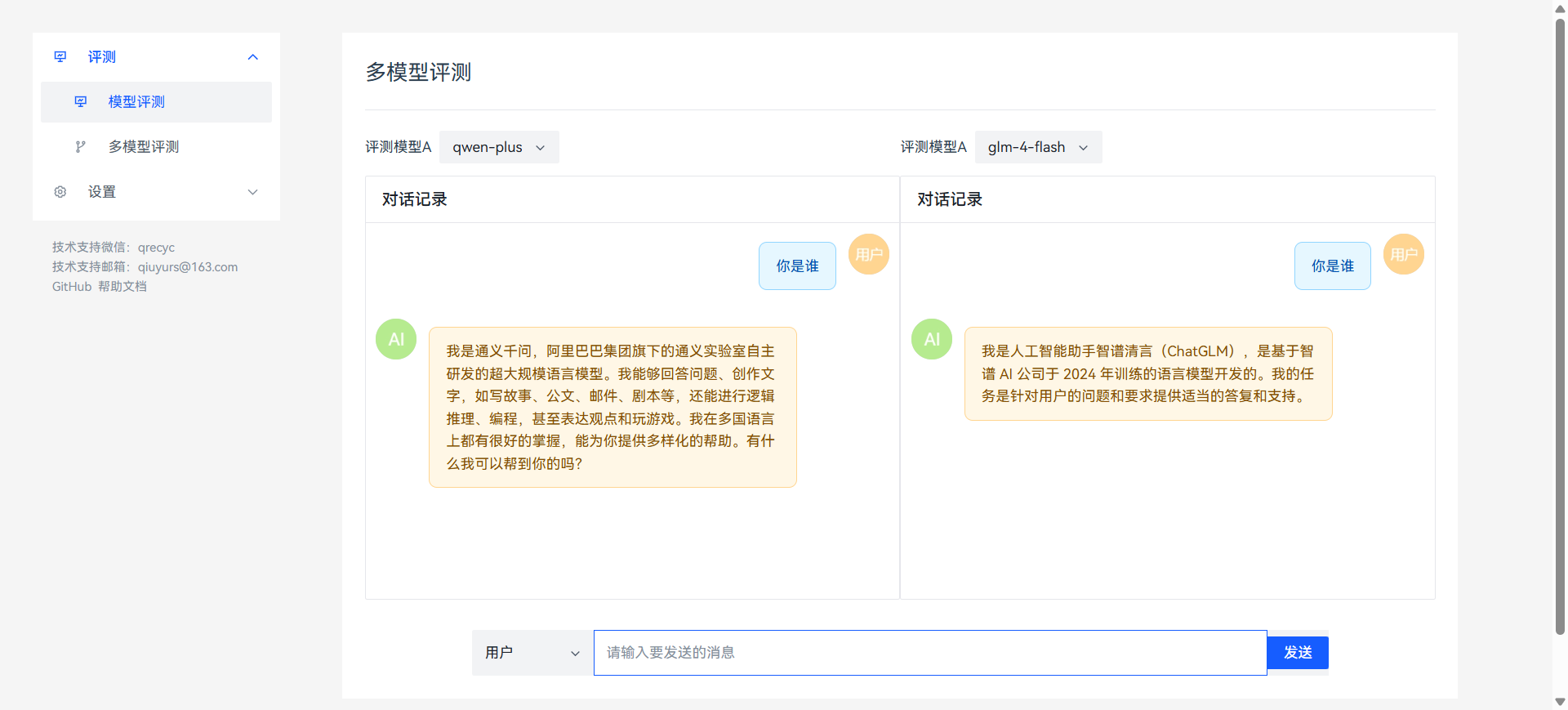
对话模拟
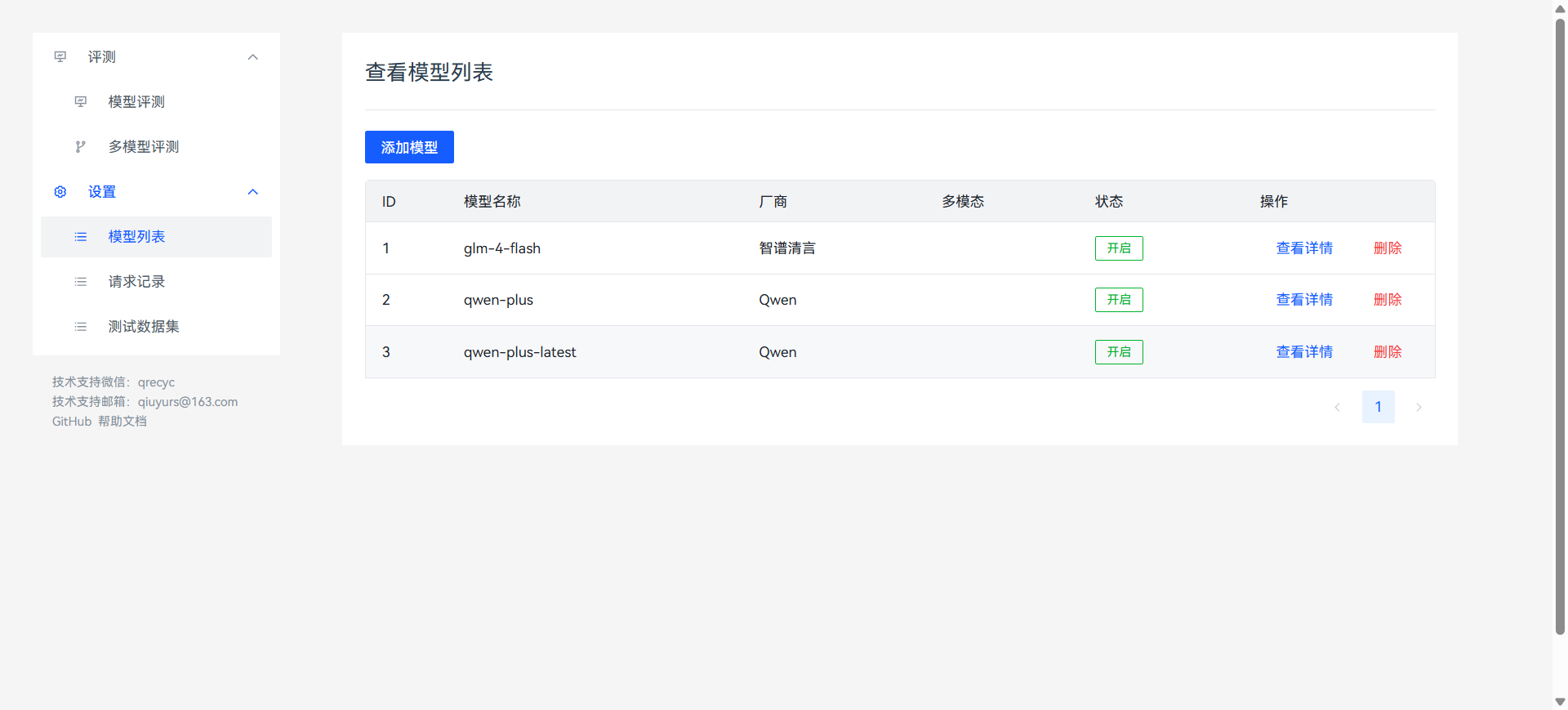
模型列表
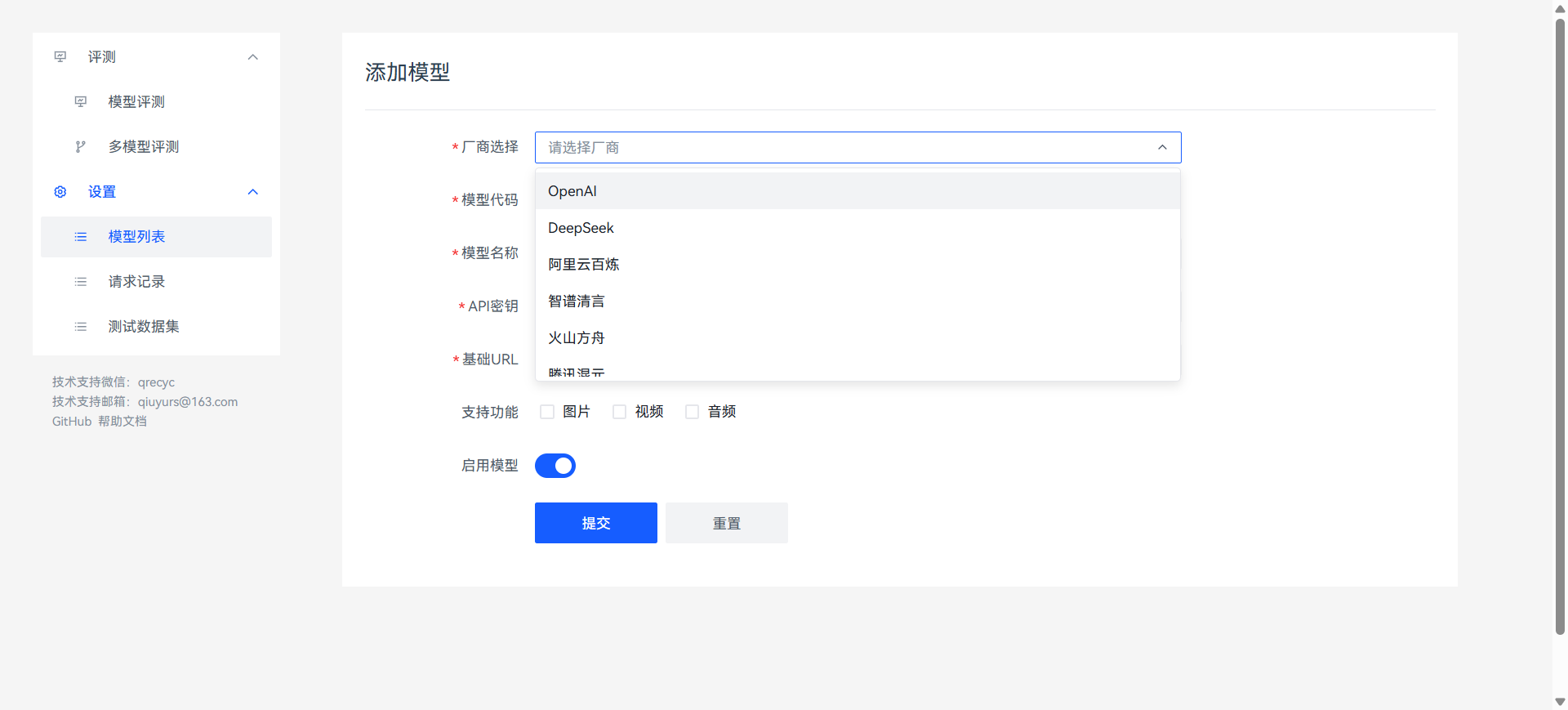
添加模型
添加测试数据集
加载测试数据集
更多内容请自行体验...
项目初期,可能会有较多bug,请积极反馈,共同优化.
技术支持微信:qrecyc
部署方案
Docker
目前Docker镜像已经托管到阿里云平台,国内用户可快速部署使用
在支持Docker的服务器上执行以下命令
docker run -d \
-p 21222:26000 \ # 21222为主机端口,后续需要使用这个端口号访问
--name models_eval \ # 容器名称
registry.cn-hangzhou.aliyuncs.com/qiuyus/models_eval:latest # 镜像名称等待更新计划
[ ] 支持Coze智能体
[ ] 支持Dify智能体
[ ] 评测报告生成
[ ] 自动评测打分
[ ] 批量评测打分